Dostrajanie Failover Cluster dla Hyper-V i nie tylko
W poprzednim artykule ogarnęliśmy ruch między węzłowy, a w szczególności CSV. Tym razem zajmiemy się podkręceniem Clustra, aby działał jak najbardziej niezawodnie.
Błąd typu Operating System failure (Windows bug check, STOP: 0x0000009E (blue screen).
Czasami się zdarza się, że usługa Cluster przez chwile nie odpowiada, a my nie lubimy blue-screenów i aby zapobiec błędom STOP w przypadku braku odpowiedzi usługi Cluster należy wykonać:
(Get-Cluster).HangRecoveryAction=1
Inne parametry to:
0 = Wyłączenie mechanizmu
1 = Logowanie zdarzenia
2 = Zatrzymanie usługi Cluster
3 = Wygenerowanie błędu Stop STOP: 0x0000009E
Idąc dalej podobne ustawienia należy wykonać dla dysków Clustrowych.
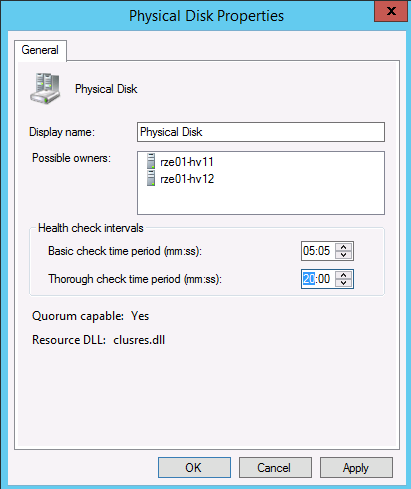
Basic check – to tzw. Podstawowy (LooksAlive Health Check) – kiedy zostanie wykonany i zwrócona zostanie wartość True – oznacza, że dysk “powinien działać”
Bardziej Zaawansowany test to Thorough check (IsAlive), wykonywany co określony czas oraz jeżeli test podstawowy zwrócił błąd.
W przypadku bardziej obciążonego systemu warto te czasy wydłużyć, co pozwoli uniknąć błędów zwłaszcza podczas backupu, objawiających się tym iż maszyna wirtualna straciła połączenie do dysku.
LooksAlive: By default, a brief check is performed every 5 seconds to verify that a disk is still available. The LooksAlive check determines whether a resource flag is set. This flag indicates that a device has failed. For example, a flag may indicate that periodic reservation has failed. The frequency of this check is user definable.
IsAlive: A complete check is performed every 60 seconds to verify that the disk and the file system can be accessed. The IsAlive check effectively performs the same functionality as a “dir” command that you type at a command prompt. The actual command it uses is the “FindFirstFile()” API. The frequency of this check is also user definable.
Podobnie jak ustawienia dotyczące dostępnego komponentu, takiego jak dysk mamy też ustawienia dot. poszczególnych zasobów. I tak dla maszyn wirtualnych, aby w przypadku obciążenia za szybko nie były uznawane, za niedziałające proponuje ustawić następujący parametr.
(Get-ClusterResourceType “Virtual Machine”).DeadlockTimeout = 990000
Idąc dalej jeżeli maszyna wirtualna, zwłaszcza przy obciążonym systemie nie startuje I pojawi się błąd:
Cluster resource <Resource> timed out. If the pending timeout is too short for this resource, consider increasing the pending timeout value.
Wówczas warto zwiększyć czas potrzebny na uruchomienie się, zwłaszcza dużej maszyny:
(Get-ClusterResourceType “Virtual Machine”).PendingTimeout=800000
(Get-ClusterResourceType “Virtual Machine Configuration”).PendingTimeout=800000
W celu zwiększenia wydajność podsystemu dyskowego CSV warto włączyć Cache wykonując z PowerShell’a:
(Get-Cluster).BlockCacheSize=1024 #Zwiększenie cache do 1 GB – zalecam zwiększenie do 2GB
Jako, że jedna lub niedoborze, kilka maszyn wirtualnych mogą wysycić nam sieć i związaną z kartą sieciową procesor oraz tym bardziej dysk dlatego sugeruje wprowadzenie ograniczeń, i ograniczyć dla dysku maksymalnie 10000 IOPS:
get-vm|Get-VMHardDiskDrive|Set-VMHardDiskDrive -MaximumIOPS 10000 -MinimumIOPS 8000
Informacja dotycząca minimalnej liczby IOPS – w przypadku osiągniecia tejże wartości odpowiedni wpis zostanie zapisany i będzie można go podejrzeć za pomocą Event Viewer’a.
Ograniczenia dla karty sieciowej maszyny wirtualnej:
Get-VMNetworkAdapter -All|Set-VMNetworkAdapter -MaximumBandwidth 300Mb
Powyższe polecenie skonfiguruje również partycje 0, czyli system operacyjny Hyper Visor’a również będzie podlegał ograniczeniom, co nie jest zalecane – dlatego, proponuje wykonać:
Get-VMNetworkAdapter -ManagementOS |Set-VMNetworkAdapter -MaximumBandwidth 50000Mb
A wszystko w celu, aby maszyny wirtualne nie wysyciły sieci i procesora, bo sieć w rozwiązaniach typu Cluster jest bardzo ważna. To przez nią odbywa się ruch HeartBeat, który jest bardzo ważny i powinien być traktowany priorytetowo. Jeżeli poszczególne nody Clustra stracą kontakt na ponad 20 sekund ze sobą po wszystkich sieciach, dla których zdefiniowany jest HeartBeat wówczas taki nod wypadnie z Clustra i wszystkie zasoby z niego zostaną przeniesione na innego noda. Możemy to stwierdzać analizując log Clastrowy, który możemy pobrać komendą:
Get-ClusterLog -Destination C:\AnalizaLogow -UseLocalTime
A w nim zobaczymy takie wpisy:
Line 13821: 00001cd4.000145bc::2018/06/11-10:40:54.588 INFO [IM] Marking Route from 10.11.105.12:~3343~ to 10.11.105.11:~3343~ as down
Line 13960: 00001cd4.000145bc::2018/06/11-10:40:54.591 INFO [IM] Marking Route from 192.168.11.8:~3343~ to 192.168.11.3:~3343~ as down
W Event Viewerze bądą to wpisy:
Cluster network interface node1 – Heartbeat’ for cluster node node1 on network ‘heartbeat’ failed.
Cluster Shared Volume Volume has entered a paused state because of ‘(c0000203)’. All I/O will temporarily be queued until a path to the volume is reestablished.
Cluster node ‘waw01-hpv36’ was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster.
Warto wspomnieć, że komunikacja HeartBeat odbywa się z wykorzystaniem protokołu UDP i dlatego warto zwiększyć owy czas, że nod clustra nie widzi innych nodów, np. ze względu na jego przeciążenie. Maksymalnie możemy zwiększyć czas do 120 sekund.
(Get-Cluster).sameSubnetThreshold=120
(Get-Cluster).crossSubnetThreshold=120
Dochodzimy do setna, jak już wspomniałem sieć jest bardzo ważna w komunikacji i wykorzystywana jest przynajmniej w 4 wartstwach (W przypadku wirtualizacji):
- LiveMigration;
- Ruch CSV;
- HeartBeat;
- Komunikacja maszyn wirtualnych;
- Komunikacja administracyjna np. Przegrywanie plików, backupów.
Powyższe opisywałem w poprzednim artykule, a teraz zajmiemy się obciążeniem procesor versus Karta Sieciowa i maszyna wirtualna. Aby ruch sieciowy wygenerowany przez maszynę wirtualną rozkładał się na poszczególne procesory – i to nie na procesor “0”, który i tak ” ma co robić” powinniśmy włączyć i skonfigurować VMQ.
Get-NetAdaptervmq # Wyświetlenie informacji

To do czego powinniśmy doprowadzić, to aby każda karta była przypisana do innego procesora (core) i robimy to za pomocą polecenia:
Set-NetAdapterVmq -Name “SLOT 3 Port 2” -BaseProcessorNumber nr_procesora
Jeżeli karty pracują w Team (co jest zalecane) wówczas każda z kart powinna wykorzystać maksymalnie połowe procesorów (przy założeniu, że w teamie są 2 karty sieciowe), w przypadku trzech kart sieciowych wartość 1/3 itd.
-MaxProcessors ilość_procesorów
Powyższe ma zastosowanie tylko wtedy, gdy włączmy VMQ, co jest zalecane dla kart o szybkości powyżej 1GB. Dla kart 1 GB i Broadcom nie jest to zalecane, a bynajmniej należy się upewnić, iż mamy aktualny sterownik. Oczywiście w założeniu mam, że dana karta sieciowa wykorzystywana jest przez maszyny wirtualne.
Robimy to dodając parametr.
-Enabled $True
Przykład komendy:
Set-NetAdapterVmq -Name “SLOT 3 Port 2” -BaseProcessorNumber 3 -MaxProcessors 16 -Enabled $True
W przypadku kiedy mamy używane HT w procesorach BaseVmqProcessor może być tylko parzysty.
Dodatkowo jeżeli w jednym Teamie pracują 2 karty sieciowe Max Processors nie może na siebie nachodzić. Czyli jeżeli pierwsza karta używa procesora 2 i mamy MaxProcessors na 14, wówczas pierwsza karta może używać procesora 2,3,4,5,6,7,8,9,10,12,12,13,14,15. A drugą kartę powinniśmy ustawić, iż używa procesora 16 i max Processors również na 14.
Aby maksymalnie wykorzystać moc karty sieciowej powinniśmy ustawić Receive Buffers na maksymalną wielkość, dla różnych kart będą to wielkości typu 4096, 2048 lub Maximum.
Odczyt aktualnej wielkości:
Get-NetAdapterAdvancedProperty “SLOT 3 Port 2” -DisplayName “Receive Buffers”
Ustawienie:
set-NetAdapterAdvancedProperty “SLOT 3 Port 2” -DisplayName “Receive Buffers” -DisplayValue 4096
lub
set-NetAdapterAdvancedProperty “SLOT 3 Port 2” -DisplayName “Receive Buffers” -DisplayValue “Maximum”
Na zakończenie pamiętajmy, iż we współczesnych systemach domyślnie włączony jest Multichanel dla ruchu SMB, a więc przy kopiowaniu plików użyte zostaną wszystkie kary sieciowe, co z kolei może wysycić ruch na karcie HeartBeat i CSV.
Wyłącznie multichanel:
Set-SMBClientConfiguration –EnableMultichannel $False
Set-SmbServerConfiguration -EnableMultiChannel $false
Mariusz Ferdyn
Gdyby były jakieś pytania zapraszam do kontaktu.
PS:
Pomyślcie też czy maszyna wirtualna musi przenosić się na inny nod clustra w przypadku braku sieci:
get-vm|Set-VMNetworkAdapter -NotMonitoredInCluster $True